CVPR 2016 · 论文精读
VDSR
Accurate Image Super-Resolution
Using Very Deep Convolutional Networks
Jiwon Kim, Jung Kwon Lee, Kyoung Mu Lee · Seoul National University
背景 · 三痛点
VGG · 深度 + 3×3
贡献 · 四件套
方法 · 残差 + 极深
实验 · 全图表分析
FIG. 1 · Set5 · PSNR vs running time
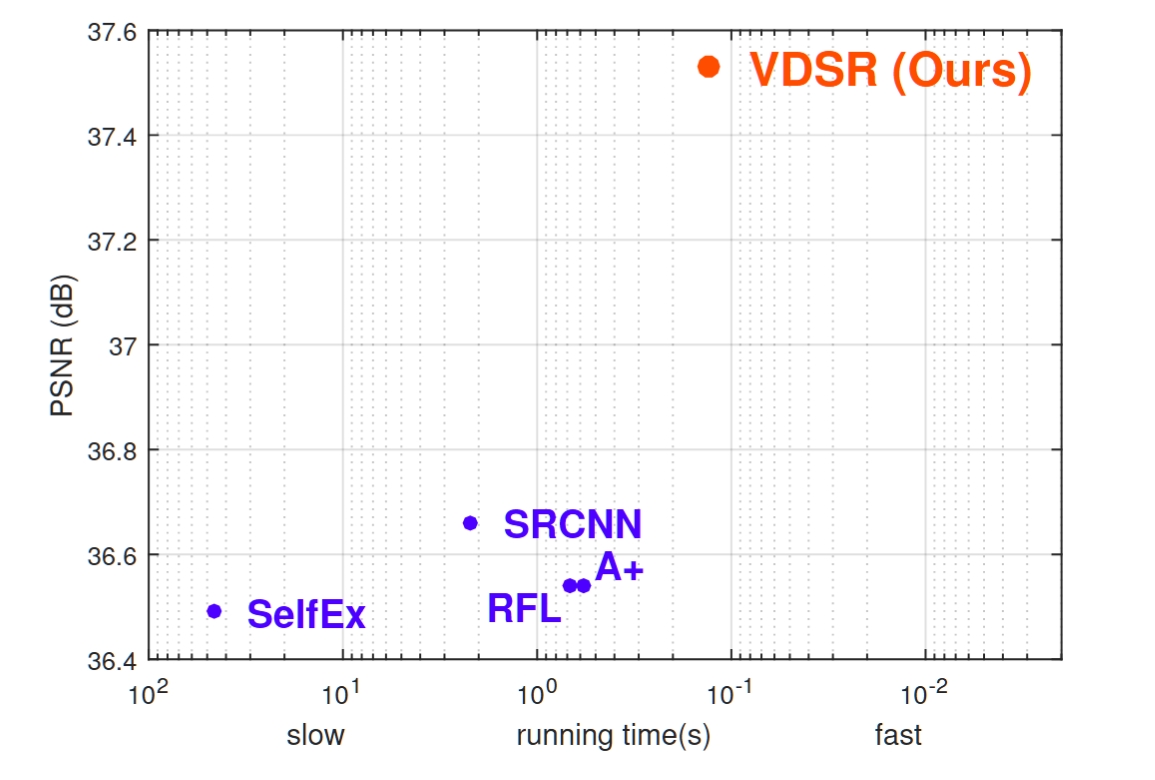
+0.87dB
over SRCNN on Set5 ×2
20 层 · 残差学习 · 单网络多尺度
20 层 · 残差学习 · 单网络多尺度
PART 01 / 04
研究背景
SRCNN 三个痛点 · VGG 论文给出的三个启发
SRCNN(2014)只有 3 层卷积,作者 Dong et al. 尝试加深却无法收敛 / 性能反退。VDSR 把这归因为三个具体问题,并各自给出对策。
①
感受野太小
SRCNN 只 3 层 · 3×3 等小核 ⇒ 感受野约 13×13,只能看到局部小块,无法利用全局上下文。
②
深度↑ ⇒ 收敛慢
加深网络要么训练太慢、要么梯度爆炸 / 消失。SRCNN 学习率被压到 \(10^{-5}\),一周还没收敛。
③
单一尺度
SRCNN 一个模型只能做一个 scale;想做 ×2/×3/×4 要训 3 个网络,存储 / 部署都不友好。
只学习残差 · Residual Learning
— 把"难任务"拆成"简单任务 + 一点修正"
x输入 · LR 图经 bicubic 插值放大到目标尺寸("模糊版" HR,约 33 dB)
y真值 (HR) · 原始高分辨率图像(训练时已知,推理时要预测)
r残差 · \(r = y - x\),主要是边缘 / 纹理等高频信息
直觉 · 两种学习目标对比
❌ 朴素
x (LR↑)
→
CNN · 20 层
→
y (整张 HR)
网络要从零"画出"整张 HR — 但 HR 里 95% 的信息(低频)其实早就在 x 里了。让网络重新学一遍低频是浪费容量、收敛慢。
✔ VDSR
x (LR↑)
→
CNN · 20 层
→
r (残差)
+ x
→
y
$$y = x + \color{#b45309}{r} \quad \Longrightarrow \quad \color{#b45309}{r = y - x}$$
网络只学高频差异 r(残差),低频通过跳连直接传递
为什么残差好用 · 三个直觉
① 任务变简单
r 大多接近 0,只在边缘 / 纹理处有值。网络容量集中用于高频细节,不必重学整张图。
② 梯度直通
x 通过跳连(skip)直接加到末层。反向传播时梯度从输出 "直达"输入,不会被 20 层卷积稀释 ⇒ 解决梯度消失。
③ 起点已很好
x = bicubic 已经是"近似答案"(约 33 dB)。从这个起点出发只需小修正,所以可以用大 100,000× 的学习率而不发散。
三个问题虽然各自独立,但 VDSR 一次性解决:极深 + 残差 + 高学习率 + 多尺度共享 —— 论文的所有创新都围绕这条主线展开。
2014 年以前,业界普遍相信"大卷积核 + 浅而宽"是 CNN 的正解。VGG(Simonyan & Zisserman, ICLR 2015)用一次极限实验把这个共识彻底打翻 —— 这次思想暴击,正是 VDSR 突破 SRCNN 瓶颈的核心钥匙。
BEFORE VGG · 思维定势
不敢做深 · 依赖大核
\(11{\times}11\)
→
\(5{\times}5\)
→
\(3{\times}3\)
AlexNet (2012) · ZFNet (2013) · 又宽又浅 · ≤ 8 层
为什么当时业界这么相信?
- 类比传统手工特征:SIFT/HOG 用大模板抓"整块结构",CNN 自然沿用 — 大核 = 大感受野 = 一步抓住完整轮廓
- AlexNet 2012 的成功路径依赖:它用 \(11{\times}11\)/\(5{\times}5\) 拿下 ImageNet,业界默认"这个配方就是对的"
- 深网根本训不动:初始化粗糙 ⇒ 梯度消失 / 爆炸,10 层以上几乎必崩
- 算力 & 显存吃紧:2014 之前单卡 GPU 只有 3–6 GB,深网装不下也算不起
- 直觉错误:"层数 ≈ 复杂度,加几层就够",没人系统性消融过深度
⇨
范式转移
THE VGG PHILOSOPHY · 极简美学
统一极简 · 系统性加深
…
VGG · 19 层全 \(3{\times}3\) · 积木式堆叠
VGG 的三记反手
- 抛弃花哨设计:全网只用 \(3{\times}3\) 卷积 + ReLU,零特殊层;结构清晰、可无限堆叠
- 系统性消融深度:固定其他参数把层数 11 → 13 → 16 → 19,证明 Top-5 误差单调下降、未饱和
- 参数代价几乎为零:11 → 19 层,参数仅从 133M → 144M(+ 8%)— 多层 \(3{\times}3\) 比单层大核还便宜
- 数学保证:3 个 \(3{\times}3\) ≡ 1 个 \(7{\times}7\) 感受野,但参数 \(-45\%\) + ReLU 数 \(\times 3\)
这一次思想暴击给 VDSR 的核心遗产:"选一个简单到不能再简的组件 \((3{\times}3\) 卷积 + ReLU\),系统性地把深度推到极限。" — VDSR 完全照搬这条方法论。接下来两页拆开看:为什么必须"深"?为什么必须是 \(3{\times}3\)?
感受野(Receptive Field, RF)= 深层特征图上一个像素,能"看到"输入图上多大区域。这个区域越大,网络在做决策时能利用的上下文越多 — 这是 VDSR 用 \(41{\times}41\) 完虐 SRCNN \(13{\times}13\) 的根本原因。
几何直觉 · 从顶部像素"反向投影"到输入
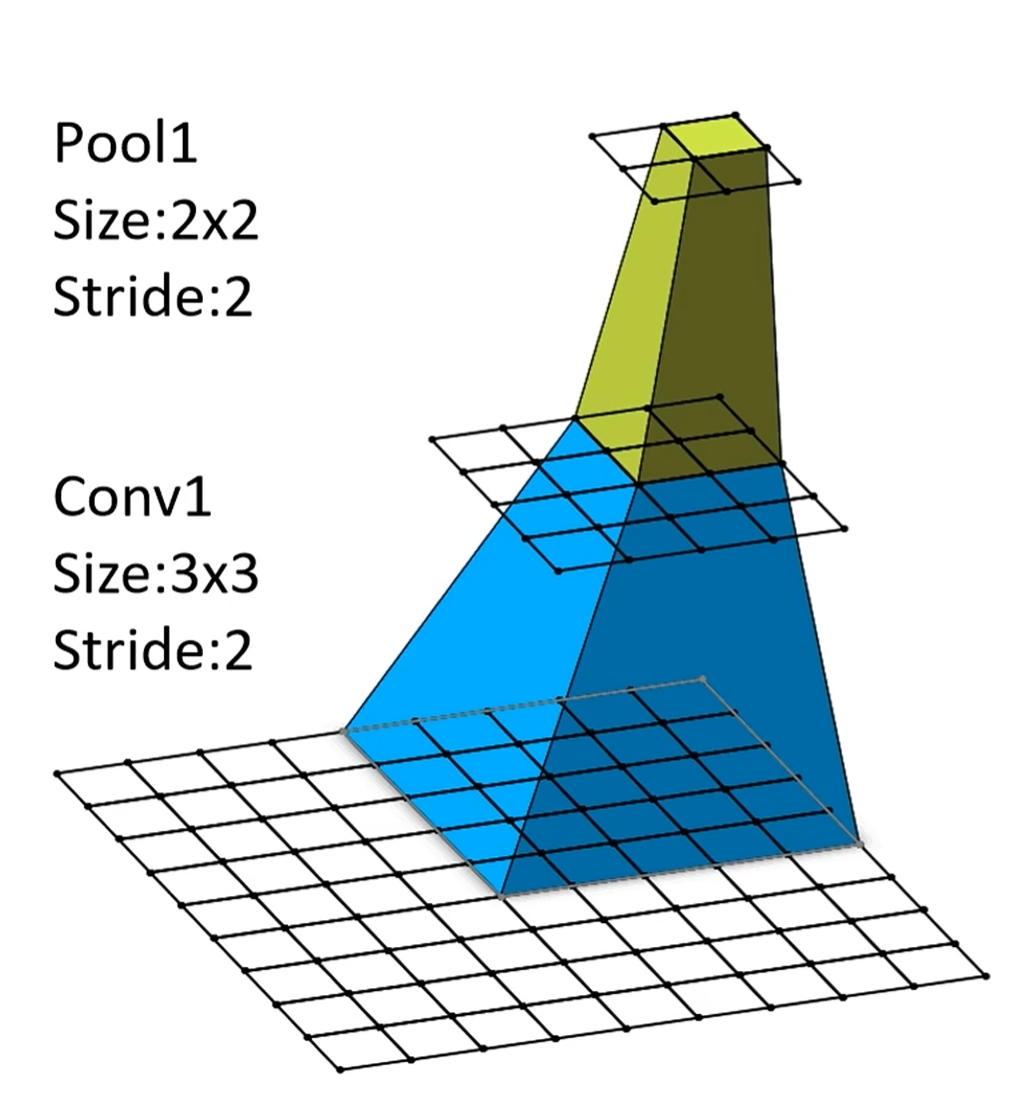
绿色顶点 = Pool1 输出上的一个像素
蓝色中层 = 它在 Conv1 上"看到"的 \(3{\times}3\) 区域
底层网格 = Conv1 在原输入上覆盖的区域 = 该顶点的感受野
蓝色中层 = 它在 Conv1 上"看到"的 \(3{\times}3\) 区域
底层网格 = Conv1 在原输入上覆盖的区域 = 该顶点的感受野
核心:感受野只跟核大小、stride、层数有关,跟通道数无关。
换个角度想:把网络"从上往下"展开 — 每经过一个卷积层,每个像素的"视野"就被它的核扩张一次;每经过一次 stride/pool,扩张速度乘以 stride 倍。
通用递推公式 · 从顶端"回看"输入
$$F(i) = \big(F(i+1) - 1\big) \times \text{Stride} + \text{Ksize}$$
\(F(i)\) = 第 \(i\) 层的感受野
\(\text{Stride}\) = 第 \(i\) 层的步距
\(\text{Ksize}\) = 第 \(i\) 层的卷积核 / 池化核尺寸
初值:最深层 \(F(L{+}1)=1\)(一个点),从后往前逐层推
\(\text{Stride}\) = 第 \(i\) 层的步距
\(\text{Ksize}\) = 第 \(i\) 层的卷积核 / 池化核尺寸
初值:最深层 \(F(L{+}1)=1\)(一个点),从后往前逐层推
🎯 VDSR 的特例:所有层 \(\text{Ksize}=3\)、\(\text{Stride}=1\) ⇒ 公式化为
\(F(i)=F(i+1)+2\),每往前一层 RF \(+2\);20 层累积 \(F = 1 + 2{\times}20 = 41\),即 \(41{\times}41\)。
逐层推算 · \(3{\times}3\) · stride 1 · \(D\) 层
| 层数 \(D\) | 新增范围 | 累积 RF | 典型代表 |
|---|---|---|---|
| 1 | \(+2\) | \(3\times 3\) | 单层 conv |
| 3 | \(+2\) | \(7\times 7\) | SRCNN(\(9{+}1{+}5\) 大核组合 ≈ \(13\)) |
| 10 | \(+2\) | \(21\times 21\) | 中等深度 |
| 20 | \(+2\) | \(41\times 41\) | VDSR ★ |
小结:感受野是网络"看世界的视野"。下一页回答 为什么 SR 任务非要这么大的视野;再下一页回答 为什么用堆 \(3{\times}3\) 而不是直接上大核。
VGG(Simonyan & Zisserman, 2015)的核心实验:固定其他参数,只改变深度,把 11 层一路加到 19 层 — Top-5 误差持续下降,且参数总数仅从 1.33 亿略增到 1.44 亿。深度本身就是性能因子。
VDSR 应用:感受野随深度线性增大
$$\text{RF}(D) = (2D+1) \times (2D+1)$$
其中 \(D\) = 仅 \(3{\times}3\) 卷积层的层数;当 \(D=20\) 时 \(\text{RF}=41{\times}41\)。
⚠ 前提:无 Pooling、stride = 1、不算 dilation。VGG 是分类任务,中间有 5 个 max-pool,感受野扩张更快;SR 任务为不丢空间细节而完全不做 pooling,VDSR 正是纯靠 \(3{\times}3\) 卷积硬把感受野堆到 \(41{\times}41\)。
SRCNN (≈3 层)
13 × 13
D = 10
21 × 21
D = 15
31 × 31
VDSR D=20
41 × 41
① 更大感受野 = 更多上下文
SR 是病态逆问题,一个 LR patch 对应无穷多 HR 可能。
⇒ 必须借助邻域 / 全局信息消歧。
⇒ 41×41 vs 13×13:覆盖区域是 SRCNN 的约 10×。
⇒ 必须借助邻域 / 全局信息消歧。
⇒ 41×41 vs 13×13:覆盖区域是 SRCNN 的约 10×。
② 更深 = 更复杂的非线性映射
20 层 ⇒ 19 次 ReLU 堆叠,每层都引入一段分段线性"折"。
⇒ 函数族能表达更复杂的边缘 / 纹理映射,而不只是 bicubic 的"软放大"。
⇒ 函数族能表达更复杂的边缘 / 纹理映射,而不只是 bicubic 的"软放大"。
💡 比喻:浅网络像用一把直尺去拟合曲线 — 怎么放都贴不上;深网络像用无数段微小折线去逼近 — 几乎能完美贴合任何复杂边缘 / 纹理。深度带来非线性,非线性带来画质。
深度的实测增益 · Set5 ×2 · PSNR / dB(论文 Fig 3 预告)
D = 5 → 20 · 4× 性能提升来自纯深度
36.46
D = 5
36.89
D = 8
36.93
D = 11
36.97
D = 14
36.89
D = 17
37.06
D = 20 ★
D=5→20: PSNR 从 36.46 → 37.06 dB(+0.60 dB),曲线单调上升、未见饱和。论文坦言"更深可能更好,4 小时训练预算所限,留作 future work"。
从 VGG 学到的: "把简单的好主意(3×3 卷积 + ReLU)推到极限"。VDSR 把这个哲学搬到 SR:固定 3×3、固定通道数 64,只把 D 拉到 20。
VGG 论文 2.3 节专门论证:三个串联的 3×3 与一个 7×7 拥有相同感受野,但前者参数少 45% 且非线性更强。这是 3×3 成为现代 CNN 默认核大小的关键论证。
感受野等价 — 三层 3×3 = 一层 7×7
① 非线性增强 · 隐式正则化
3 个 \(3{\times}3\) = 3 个 ReLU 决策面,函数族更具判别力;1 个 \(7{\times}7\) 只有 1 个 ReLU。
💡 正则化通俗版:用三层 \(3{\times}3\) 替代一层 \(7{\times}7\) = 参数减半 + ReLU 数翻三倍。逼网络在更严的容量限制下做更复杂的决策 —— 天然抑制过拟合。VDSR 正是看准了这一点才敢叠到 20 层而不爆参数。
② 参数效率 · 暴降 45%
\(27\,C^2\) vs \(49\,C^2\) ⇒ 参数节省接近一半(\(\tfrac{49-27}{49}\approx 45\%\))。
同感受野下,3×3 让网络更深 / 更宽都成为可能。
同感受野下,3×3 让网络更深 / 更宽都成为可能。
VDSR 的选择
所有 20 层都用 3×3·64 通道,零变化 — 把 VGG 的"统一极简"哲学搬到 SR。
推广 · \(N\) 层 \(3\times3\) ≡ 1 层 \((2N+1)\times(2N+1)\) — 参数节省随 \(N\) 增大而扩大
参数比 \(=\dfrac{9N}{(2N+1)^2}\)
| N(3×3 层数) | 等效核 | \(N\cdot 3^2\cdot C^2\) | \((2N+1)^2\cdot C^2\) | 参数节省 | ReLU 个数 |
|---|---|---|---|---|---|
| N = 2 | 5×5 | \(18\,C^2\) | \(25\,C^2\) | −28% | 2 · vs · 1 |
| N = 3 | 7×7 | \(27\,C^2\) | \(49\,C^2\) | −45% | 3 · vs · 1 |
| N = 5 | 11×11 | \(45\,C^2\) | \(121\,C^2\) | −63% | 5 · vs · 1 |
| N = 20 · VDSR | 41×41 | \(180\,C^2\) | \(1681\,C^2\) | −89% | 19 · vs · 1 |
\(N\) 越大 ⇒ 节省越激进,且非线性能力呈 \(N\) 倍线性增长。这正是 VGG/VDSR 敢把网络叠到 19/20 层的底层数学保证 — 同样感受野下,叠小核既省参数又增表达力,是真正的"双赢"。
VGG 是为分类任务(高层视觉)设计的;VDSR 是超分辨率(低层视觉)。两个任务对网络的需求不同 — 哪些 VGG 设计可以照搬,哪些必须改?这张图给出对照。
| 设计维度 | VGG 的设计(分类任务) | VDSR 怎么处理(SR 任务) | 判定 |
|---|---|---|---|
| 卷积核 | 所有卷积核 = 3×3,stride 1,pad 1 | 完全照搬 — 20 层全部 3×3·64 | ✓ 照搬 |
| 通道数 | 每个 max-pool 后通道翻倍 (64→128→256→512) | 改为全程 64 通道不变 — SR 不需要日益抽象的语义特征 | ✎ 简化 |
| 下采样 | 5 个 max-pool 层(空间分辨率 ÷ 32) | 完全去掉 — SR 需要保留像素级空间信息 | ✗ 去除 |
| 输出层 | 末端 3 个全连接层 (4096 / 4096 / 1000) | 完全去掉 — 末层 conv 直接输出整张残差图 | ✗ 去除 |
| 激活函数 | ReLU 激活,所有隐藏层 | 完全照搬 — 19 个 ReLU(layer 1 到 19 之后) | ✓ 照搬 |
| 归一化 | 不使用 LRN(VGG 4.1 节验证无效) | 同样不用 — 验证 VGG 的结论也适用于 SR | ✓ 照搬 |
| 边界处理 | 每层 conv 后 zero-padding (size 1) | 完全照搬 — 输入输出尺寸严格一致,边缘像素也能 SR | ✓ 照搬 |
| 权重初始化 | 深网先训浅网,再用浅网权重初始化深网 | 改用 He 初始化(专为 ReLU 设计),更简单 | ✎ 替换 |
| 卷积核变体 | 1×1 conv(配置 C 实验用,但 D 更好) | 不用 — 全 3×3 已经够强 | ✗ 不用 |
| 优化器 | SGD + momentum 0.9 | 完全照搬 — SGD + momentum 0.9 | ✓ 照搬 |
| 权重衰减 | L2 weight decay = 5e-4(batch 256) | 调小到 1e-4(1/5)· batch 64 — 配合 10× 学习率 | ✎ 调整 |
深挖 · 唯一一个"数值被改"的超参
为什么 weight decay 要从 5e-4 调到 1e-4?
① 与 10× 学习率耦合
真正决定权重压缩力度的是 \(\eta\cdot\lambda\)。VGG:\(0.01\times 5\text{e-}4=5\text{e-}6\);VDSR 若保留 5e-4 ⇒ \(0.1\times 5\text{e-}4=5\text{e-}5\),暴增 10×。调到 1e-4 ⇒ \(1\text{e-}5\),与 VGG 同数量级。
② SR 过拟合风险低
VDSR 仅 ~665K 参数(VGG-16 的 1/200);回归任务而非分类;291 张图切成数十万 patch — 数据其实很充足,不需强正则化。
③ 已有其他正则化补充
自适应梯度裁剪 + 残差学习(目标 \(r\approx 0\) 本身就接近零)天然抑制过拟合,weight decay 的角色可以放轻。
本质:"高学习率 0.1 + 小 weight decay 1e-4 + 梯度裁剪 + 残差学习"是一个互相耦合的系统 —— 动一个,其余都要跟着动。VDSR 不是照搬 VGG,而是以 VGG 为起点针对 SR 任务做系统性调参。
SR 历经 三个阶段: 插值 / 字典 / 神经网络。直到 SRCNN 才把 CNN 拉进战场,但停在 3 层 — VDSR 接力把它推向深度。
早期方法
插值 + 字典学习
- Bicubic / Lanczos:固定多项式插值
- Neighbor Embedding (Chang 2004) / Sparse Coding (Yang 2010):LR-HR patch 字典
- A+ (Timofte 2014) · RFL · SelfEx — 当时的强基线
✗ 都基于手工特征,难以利用大上下文
SRCNN (2014)
第一个 CNN-based SR
- 3 层 CNN: patch 提取 → 非线性映射 → 重建
- PSNR 比传统方法 +1 dB 以上
- 输入是 bicubic 已放大的 ILR
✗ 只有 3 层、感受野小、慢、单尺度
VGG (2015)
深度 = 性能 · 3×3 = 最优
- 11 → 19 层渐进实验,Top-5 误差持续下降
- 仅用 3×3 + ReLU 的统一架构
- ImageNet 2014 定位/分类 1/2 名
✓ VDSR 直接借鉴: 20 层 · 全 3×3 · 全 ReLU
VDSR 的位置:把 VGG 在高级视觉(分类)的"深度+小核"哲学,第一次成功带到低级视觉(超分),并叠加 SR 任务特定的残差学习。
细节差异 ① · Padding
SRCNN 不 pad ⇒ 每过一层图像缩小,最后输出比输入小若干圈像素。
VDSR 每层零填充 ⇒ 输入输出尺寸完全一致,边缘像素也能被超分。
VDSR 每层零填充 ⇒ 输入输出尺寸完全一致,边缘像素也能被超分。
细节差异 ② · 学习率
SRCNN 前两层 \(\text{lr}=10^{-4}\)、第三层 \(10^{-5}\),逐层手调。
VDSR 所有层同 \(\text{lr}=0.1\),每 20 epoch \(\times 0.1\),简单统一。
VDSR 所有层同 \(\text{lr}=0.1\),每 20 epoch \(\times 0.1\),简单统一。
PART 02 / 04
贡献
在 SRCNN 的基础上 + 借鉴 VGG,VDSR 给出四件套
Slide 03 提出了 SRCNN 的三个痛点(感受野小 / 收敛慢 / 单尺度),Slide 04-08 看到 VGG 给出的方法论。把这两条线交叉在一起,VDSR 给出了四个紧密耦合的贡献 — 缺一个都会失败。
01
极深网络 · 20 层全 3×3
受 VGG 启发 · 解决问题 ①
首个真正"深"的 SR 网络。感受野 \((2D+1)^2 = 41\times 41\)(D=20),约 SRCNN 的 \(10\times\) — 一个像素能看到整片纹理 / 整条线,大幅缓解 SR 的病态性。
应对: 感受野小 · 性能: +0.87 dB on Set5 ×2
02
残差学习 · \(y = x + r\)
SR 任务特有 · 解决问题 ② 之半
网络只学高频细节 \(r = y - x\),低频通过长跳线直接传递。学习量小、梯度路径短 — 这是让深网真正"训得动"的关键钥匙。
应对: 深网难训 · Table 1 验证: 10 epoch 即达 36.90 dB
03
高 lr + 可调梯度裁剪
训练技巧 · 解决问题 ② 之半
初始 \(\text{lr}=0.1\)(SRCNN 的 \(10^4\) 倍),梯度裁剪范围跟随 lr 缩放:\(g \in \big[-\tfrac{\theta}{\gamma},\,\tfrac{\theta}{\gamma}\big]\)。让"高 lr 加速"与"梯度爆炸"两件事兼得。
应对: 训练慢 / 梯度爆炸 · 训练时间: SRCNN 数天 → VDSR 4 小时
04
单网络 · 多尺度共享
部署友好 · 解决问题 ③
一个 VDSR 模型同时处理 ×2 / ×3 / ×4 — 训练时把不同 scale 的 patch 混入同一 batch,参数完全共享。scale 之间互为正则,对大 scale 还能涨点。
应对: 每个 scale 训一个模型 · Table 2 验证: train{2,3,4} 测 ×4 = 30.95 dB > 单×4 模型 30.86 dB
四件套相互依赖: 没有残差就不敢用大 lr;没有大 lr + 裁剪就训不动 20 层;没有 20 层感受野就不够;没有多尺度共享就不能实用部署。论文的所有实验(接下来 Part 3 + 4)都在证明这四件缺一不可。
PART 03 / 04
方法
极深网络 + 残差学习 + 高学习率 + 梯度裁剪 + 多尺度共享
核心洞察:输入 \(x\)(bicubic 放大图)与目标 \(y\)(HR)高度相似 ⇒ 网络不该重新生成整张 HR,只需预测两者的差 \(r=y-x\)。低频由蓝色旁路直接搬运,CNN 全部容量都花在高频细节上。
网络数据流 · 蓝色长跳线 = 全页主角
Fig. 2 · 论文原图 — 与上方示意图对照看(顶部特征图见下一页深读)
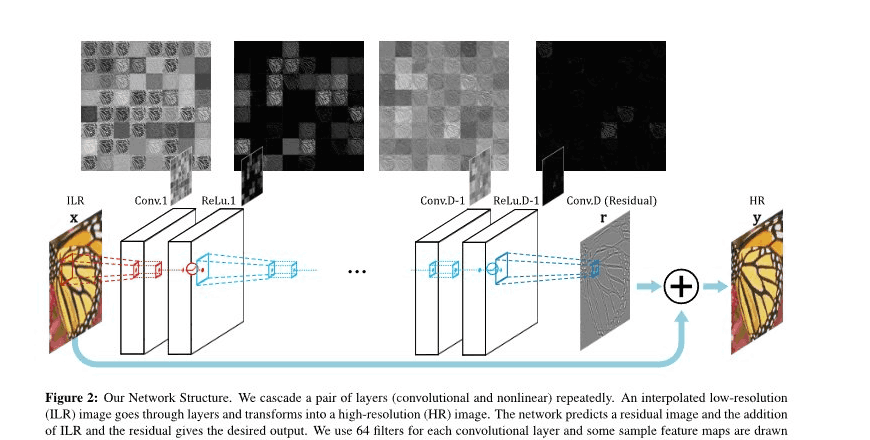
论文原图把每层卷积 / ReLU 的中间特征图也画了出来 —— 顶部那一排"马赛克方块"不是装饰,下一页专门拆解它想证明什么。
①
Deep · 20 层
感受野 SRCNN \(13{\times}13\) → VDSR \(41{\times}41\)。更大上下文 → 更准的边缘推断。
②
Residual Learning · 只学 \(y-x\)
SRCNN 学整张 HR(难);VDSR 只学残差(易)⇒ 收敛快得多(论文 Fig 4)。
③
Sparse Residual · 残差稀疏
残差大部分像素 \(\approx 0\),只在边缘激活 — CNN 不浪费参数"复制输入"。
易混淆
VDSR 是图像级残差 \(r=\text{HR}-\text{LR}\)(整张图相减);不是 ResNet 的 block 级残差 \(F(x)+x\)(特征级、每个 block 一条)。VDSR 全网只有一条全局跳连。
Fig 2 顶部那排"马赛克方块"不是装饰 —— 每个方块是 64 个滤波器之一的响应。论文图注点题:"Most features after applying ReLU are zero." 这是用视觉证据支撑"残差学习真的起作用"的核心论据。
特征图序列 · 关键不是"逐渐变黑",而是 每次 ReLU 之后"突然"变黑
Conv.1
绝大多数方块
有纹理 / 亮度
有纹理 / 亮度
ReLU
→
ReLU.1
负值被清零
大半方块变黑
大半方块变黑
··· 18 层 ···
→
Conv.D−1
仅零星方块
有微弱响应
有微弱响应
ReLU
→
ReLU.D−1
整片漆黑
≈ 全部为 0
≈ 全部为 0
Conv.D
→
Conv.D · 输出 r
一张稀疏边缘图
只在轮廓处非零
只在轮廓处非零
⚠ 纠正常见误读:特征图不是"一层层缓慢变暗",而是每次经过 ReLU \((\max(0,x))\) 把负值清零,那一步才"突然"变黑。Conv 本身有正有负、并不黑;是 ReLU 造成了稀疏。
论文展示特征图想证明的三件事
①
实证残差稀疏
"残差 \(r\) 大部分接近 0"原本只是数学设计。特征图真的全黑、输出 \(r\) 真的是稀疏边缘图 —— 眼见为实,比 PSNR 表格更有说服力。
②
解释 20 层为何不崩
ReLU 零激活 ⇒ 反传梯度也为 0。大部分激活为 0 ⇒ 活跃路径稀疏 ⇒ 网络名义 20 层、实际工作起来像 3–5 层,训练自然稳。
③
暗示隐式正则化
大量激活归零 ≈ 自动剪掉冗余连接 = 隐式稀疏正则化。这也呼应第 08 页:VDSR 因此能把 weight decay 从 5e-4 降到 1e-4。
埋下的伏笔:"稀疏激活、网络自己学会什么都不做" 这一观察,日后在 MoE 专家混合、Lottery Ticket 假说、乃至扩散模型预测噪声/残差里反复出现 —— VDSR 的这张图,看的是研究者视角,而非表面数字。
SRCNN 让网络画整张图;VDSR 让网络只画"该补的几笔"。target 简单了一个数量级,整套训练流程随之松绑。

SRCNN 画家
"从零画一只完整的蝴蝶"
target = 整张 HR \(y\)(像素 0–255)
工作量 ≈ 100%

VDSR 画家
"只补客户图里糊掉的那几笔"
target = 残差 \(r=y-x\)(多数 ≈ 0)
工作量 ≈ 5%
同样是 MSE 损失,区别只在 —— 目标图长什么样。
VDSR 的损失函数 —— 形式没变,变的是 \(\hat y\) 怎么算
① 表面:和 SRCNN 同为 MSE
$$L = \tfrac12\big\|\,y - \hat y\,\big\|^2$$
② 差异:\(\hat y\) 的计算方式变了
\(\text{SRCNN: } \hat y = f(x)\)
\(\text{VDSR: } \hat y = \color{#185FA5}{x} + f(x)\)
\(\text{VDSR: } \hat y = \color{#185FA5}{x} + f(x)\)
③ 代入展开 → 本质
$$L_{\text{VDSR}} = \tfrac12\big\|\,\color{#D85A30}{r} - f(x)\,\big\|^2$$
论文实现写成 重建视角 \(L=\tfrac12\|y-(x+f(x))\|^2\):加法节点 \(x+f(x)\) 在计算图里真实存在,梯度天然贯通 skip。代入 \(r=y-x\) 即得 残差视角 —— 两者完全等价。损失代码一个字都不用改,变的只是网络末尾加了一行 \(\hat y = x + f(x)\),optimization target 从整张 \(y\) 变成稀疏的 \(r\)。
为什么这一个改动能引发链式反应?
target ≈ 0
残差图稀疏,多数像素为 0
现象
→
loss 起步就低
初始输出≈0 即合理解,不爆炸
物理含义
→
敢用 η=0.1
大学习率,10⁴× SRCNN
敢做什么
→
20 层不发散
配合梯度裁剪兜底
结果
→
几小时收敛
收敛 ×10、PSNR 更高
最终收益
链条上抽掉任何一环,后面全崩 —— VDSR 的真正贡献不是"加一条 skip",而是用一个改动撬动了整套训练系统的重新平衡。
训练深网络要快 → 想用大学习率 但大学习率会让深网络梯度爆炸
✗ 传统方案:用小学习率慢慢爬 —— SRCNN 走的路,要数天
✓ VDSR 解法:用大学习率 + 一条聪明的"安全带"
参照基线 · 普通裁剪
\(g \leftarrow \operatorname{clip}(g,\,-\theta,\,\theta)\)
\(\theta\) 必须按初期大学习率设得很小防爆炸;可学习率衰减后 \(\theta\) 仍卡着 —— 后期有效更新被无效裁掉,训练拖慢。
→
升级
VDSR · 可调梯度裁剪
$$g \leftarrow \operatorname{clip}\!\Big(g,\;-\tfrac{\theta}{\gamma},\;\tfrac{\theta}{\gamma}\Big)$$
\(\gamma=\) 当前学习率 · \(\theta\) 仍是固定常数
关键洞察:阈值 \(\theta/\gamma\) 随学习率反向缩放 —— 学习率大时收紧防爆炸、衰减后放宽不绑架。有效步长上界恒定 \(\eta\cdot\theta/\gamma=\theta\),全程既不爆炸、也不停滞。
什么是"有效更新步长"?
SGD 每步把参数挪动 \(\Delta w = -\eta\cdot g\)(学习率 × 梯度)—— 这个挪动距离就是有效更新步长。裁剪给梯度 \(g\) 设了上限,于是步长也有上限 \(=\eta\times\)裁剪阈值。太大 → 一步迈过头、损失爆炸;太小 → 原地踏步、收敛慢。理想是让这个上限全程稳定在合理值。
80 epoch 内 · 有效更新步长上界对比
普通裁剪:阈值固定,有效步长随 lr 衰减一路下滑,后期更新被无效裁掉。
VDSR:阈值 θ/γ 反向缩放,有效步长像一把直尺,全程稳定。
VDSR:阈值 θ/γ 反向缩放,有效步长像一把直尺,全程稳定。
为什么这个简单改动这么聪明?
❶ 自适应
无需手动调度阈值,θ/γ 自动跟着学习率变化。
❷ 守护不变量
保护的是有效步长 η·g 的上界,而非梯度本身。
❸ 即插即用
一行代码 g = clip(g, −θ/γ, θ/γ),任何用 SGD 的网络都能借用。
正因有了这条"安全带",VDSR 才敢用 lr = 0.1(SRCNN 的 10⁴ 倍),把训练时间从数天压缩到数小时。这是"激进训练"系统的最后一块拼图 —— 配合上一页的残差损失,整套加速流程才能真正跑通。
SRCNN:每个 scale 单独训练、单独存储。VDSR:因为输入已经被 bicubic 放大到目标尺寸,网络 I/O 形状与 scale 无关,天然支持多尺度。
SRCNN · 一个 scale 一个模型
×2
模型 A · 训练 1 周 · 存储一份
×3
模型 B · 训练 1 周 · 存储一份
×4
模型 C · 训练 1 周 · 存储一份
×2.5
不支持 · 还要再训练一次
3 倍参数总量 · 3 倍训练时间 · 部署麻烦
VDSR · 一个模型多个 scale
训练 mini-batch(size 64):
×2 patch
×3 patch
×4 patch
×2 patch
×3 patch
×4 patch
×2 patch
×3 patch
…
不同 scale 的 patch 混在同一 batch,参数完全共享。
train = {2, 3, 4} · 单模型应付 ×2, ×3, ×4
参数 ÷ 3 · 训练时间 ÷ 3 · 还能处理 ×2.5 等分数尺度
为什么尺寸能共享?—— 关键在 bicubic 预放大这一步
机制:VDSR 的输入不是原始小图,而是已被 bicubic 放大到 HR 目标尺寸的 ILR。无论 ×2 / ×3 / ×4,喂进网络的张量形状完全一样—— scale 越大只代表模糊越重,并不改变图像尺寸。既然网络 I/O 形状与 scale 无关,卷积核就能跨 scale 复用,一套权重应付所有倍率,甚至 ×2.5 分数尺度。 下一节 Table 2 将验证:多尺度训练的单一模型,在每个 scale 上 PSNR 都追平、甚至略超对应的单尺度专用模型。
PART 04 / 04
实验
论文原图逐张精读 — 4.1 深度 · 4.2 残差 · 4.3 多尺度 · 5 SoTA
291
TRAIN IMAGES
91 (Yang et al.) + 200 (BSD)
与 RFL 对齐 · 公平 benchmark
0.1
INITIAL LR · 所有层统一
×0.1 每 20 epoch · 共 4 档
SRCNN 仅 \(10^{-4}\sim 10^{-5}\) · 手调每层
4
h
TOTAL TRAINING TIME
80 epoch · 9960 iter · Titan Z
SRCNN 训练数天到一周
SECTION 5.1
数据集
数据增强 · 单张原图 → 8 变体
rot 0°
90°
180°
270°
+ h-flip
测试集 · 四档难度(→ 渐难)
5
Set5
14
Set14
100
B100
100★
Urban100
★ Urban100(Huang 2015)含重复 / 自相似结构,旧方法常失败 — 凸显方法差异。
SECTION 5.2
训练超参
depth D20 层
batch size64
momentum0.9
L2 decay1e-4
weight initHe (ReLU)
frameworkMatConvNet
学习率衰减 · 阶梯式 4 档
0.1
.01
1e-3
1e-4
ep 1-20
21-40
41-60
61-80
VS SRCNN
SRCNN: 每层手调 lr · 训练数天到一周
VDSR: 全网 lr = 0.1 · 4 小时稳定收敛
VDSR: 全网 lr = 0.1 · 4 小时稳定收敛
SECTION 5.3
评测框架
采用 Huang et al. (CVPR 2015) 公开框架 — "用同一把尺子量所有人"。
01
PSNR / SSIM 只算 Y 通道
人眼对亮度更敏感;色度通道 bicubic。
02
边缘像素 · 统一裁切
SRCNN 等输出比输入小 — 框架统一裁。
★
VDSR 主动"吃亏"
零填充本无需裁,仍跟着裁 — 公平。
论文四大贡献
①
极深 20 层
②
残差学习
③
高 lr + 裁剪
④
多尺度共享
5 figs · 3 tabs · 8 件证据
SECTION 4
Understanding Properties
证明四件套各自有效
4.1
Fig 3
做 · 固定其他超参,深度 D = 5/8/11/14/17/20,Set5 ×2/×3/×4 测试。
证 · PSNR 随 D 单调上升、未饱和 → 更深更好。
证 · PSNR 随 D 单调上升、未饱和 → 更深更好。
①
4.2
Tab 1
做 · 3 lr × {残差 / 非残差} × 4 epoch 切片 PSNR 表。
证 · 残差 10 ep ≈ 36.90 dB · 非残差仅 27.42 → 残差让深网真正"训得动"。
证 · 残差 10 ep ≈ 36.90 dB · 非残差仅 27.42 → 残差让深网真正"训得动"。
②
③
4.2
Fig 4
做 · 3 lr 下分别画残差 vs 非残差的 80 epoch 收敛曲线。
证 · 残差(蓝)迅速稳定上升;非残差(橙)在大 lr 下震荡甚至跌破 bicubic。
证 · 残差(蓝)迅速稳定上升;非残差(橙)在大 lr 下震荡甚至跌破 bicubic。
②
③
4.3
Tab 2
做 · 7 训练 scale × 3 测试 scale 的 Set5 PSNR 矩阵。
证 · 单尺度不能跨用(train×2 测×3 = 30.05 < bicubic);多尺度对大 scale 反而更好。
证 · 单尺度不能跨用(train×2 测×3 = 30.05 < bicubic);多尺度对大 scale 反而更好。
④
4.3
Fig 5
做 · 同图在 ×1.5–×4 下视觉对比 · 上 = VDSR 多尺度 / 下 = SRCNN ×3 推所有。
证 · VDSR 全 scale 干净;SRCNN 非训练 scale 明显畸变。
证 · VDSR 全 scale 干净;SRCNN 非训练 scale 明显畸变。
④
SECTION 5
SoTA Comparison
综合贡献
5.4 · 定量
Tab 3
总成绩单
做 · VDSR vs A+/RFL/SelfEx/SRCNN,4 测试集 × 3 scale = 12 项 PSNR/SSIM。
证 · 12 项 PSNR 全部第一 · Urban100 ×2 领先 +1.26 dB → 2016 SoTA。
证 · 12 项 PSNR 全部第一 · Urban100 ×2 领先 +1.26 dB → 2016 SoTA。
①
②
③
④
综合验证
5.4 · 定性
Fig 6
建筑屋顶斜线
B100 "148026" ×3 SR · 只有 VDSR 把细线恢复成连续锐利,其他全部断裂 / 模糊。
5.4 · 定性
Fig 7
野牛犄角轮廓
B100 "38092" ×3 SR · VDSR 犄角锐利 + 对比度高;其他模糊。
证据合计
5 figs + 3 tabs = 8 件 → ①②③④ + SoTA
Fig. 3 · 论文原图 · Set5 · 深度 = 5–20 层
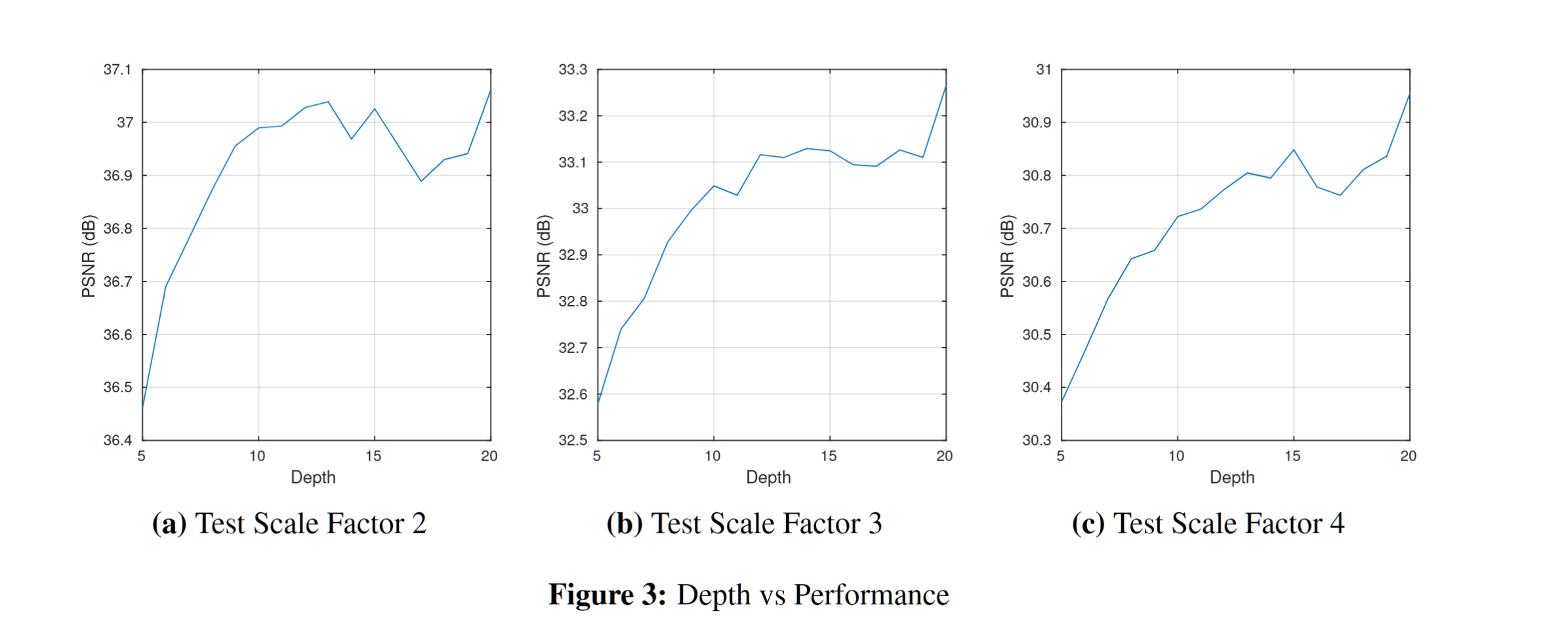
三幅图:(a) ×2 · (b) ×3 · (c) ×4。横轴 = 深度 D,纵轴 = PSNR。
实验设计
- 固定其他超参,只改深度 D
- D ∈ {5, 8, 11, 14, 17, 20}(仅算权重层)
- 在 Set5 上测试 ×2 / ×3 / ×4
三个观察
- ① 单调递增:PSNR 随 D 持续上升,没看到饱和点
- ② 大 scale 收益更大:×4 曲线斜率最陡 — 难任务对深度更敏感
- ③ 跨 scale 一致:三个 scale 都是同样的"越深越好"结论
为何选 D=20?论文实验受限于 4 小时训练预算;20 层已经显著超越 SoTA。论文承认:更深可能更好,留作未来工作。
Table 1 · Set5 ×2 · 不同初始学习率下 PSNR 随 epoch 变化
| Epoch | 10 | 20 | 40 | 80 |
|---|---|---|---|---|
| Residual | 36.90 | 36.64 | 37.12 | 37.05 |
| Non-Res | 27.42 | 19.59 | 31.38 | 35.66 |
| Δ | 9.48 | 17.05 | 5.74 | 1.39 |
(a) lr 0.1
| Epoch | 10 | 20 | 40 | 80 |
|---|---|---|---|---|
| Residual | 36.74 | 36.87 | 36.91 | 36.93 |
| Non-Res | 30.33 | 33.59 | 36.26 | 36.42 |
| Δ | 6.41 | 3.28 | 0.65 | 0.52 |
(b) lr 0.01
| Epoch | 10 | 20 | 40 | 80 |
|---|---|---|---|---|
| Residual | 36.31 | 36.46 | 36.52 | 36.52 |
| Non-Res | 33.97 | 35.08 | 36.11 | 36.11 |
| Δ | 2.35 | 1.38 | 0.42 | 0.40 |
(c) lr 0.001
红=Residual PSNR · Δ=Residual − Non-Residual · 残差网在 10 epoch 内即接近收敛
Fig. 4 · 收敛曲线 · 残差(蓝) vs 非残差(橙) vs Bicubic(红线)
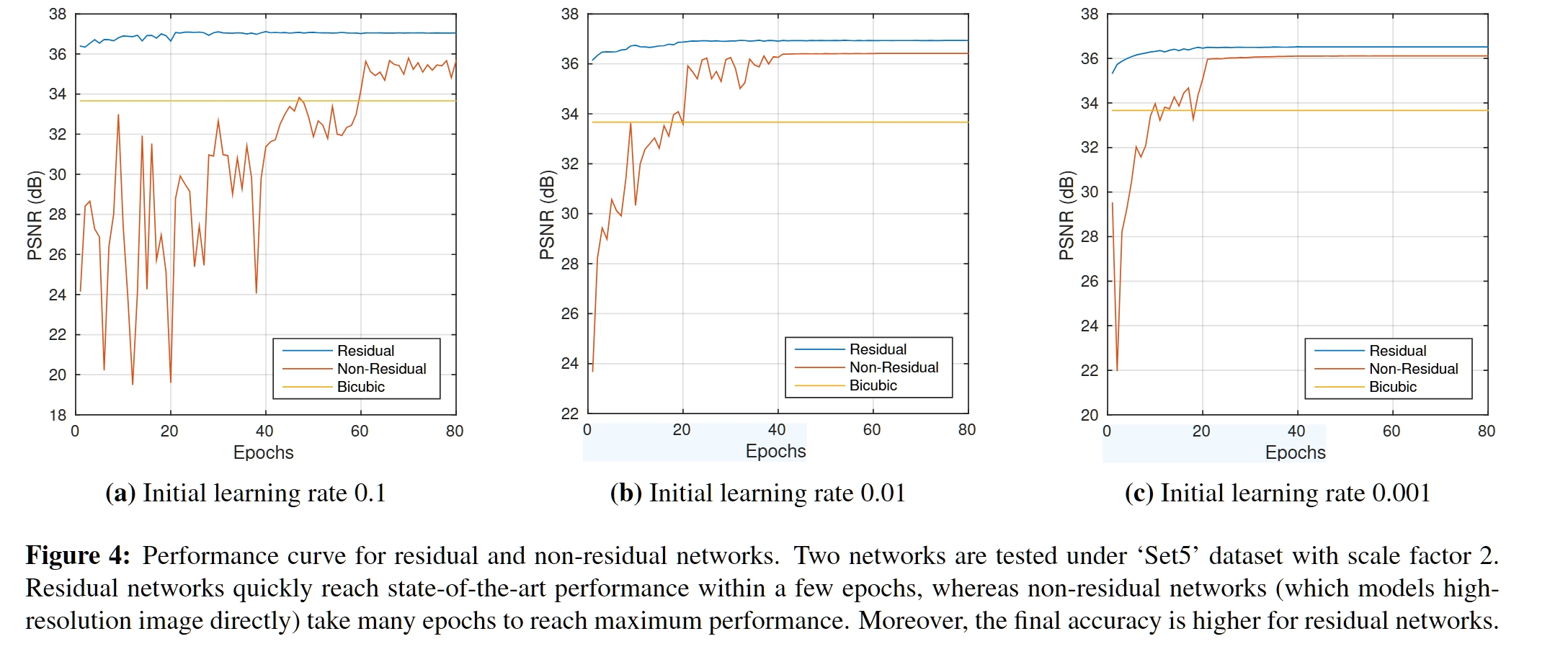
读 Table 1 的方向
- 横向:同 lr 下,看残差网随 epoch 收敛速度
- 纵向:同 epoch 下,比较残差 vs 非残差
- 三表:lr = 0.1 / 0.01 / 0.001 对比
★ 三个发现
① 残差 10 epoch 即达高峰:lr=0.1,36.90 dB;非残差只有 27.42(差 9.48 dB!)
② 残差终点更高:80 epoch 后残差 37.05 vs 非残差 35.66 — 不是收敛速度问题,是最优解差异
③ 需要配合高 lr:lr=0.001 时残差 80 epoch 仅 36.52 dB — 单独用残差不够,"高 lr + 残差 + 裁剪"是三件套
Fig 4(a) 中橙线 (非残差 + lr=0.1) 剧烈震荡 / 跌破 bicubic 红线 — 直观展示了"高 lr 没残差"的灾难性。这正是 SRCNN 不敢用大 lr 的原因。
Table 2 · Set5 PSNR · 行 = Test scale · 列 = Train scale · 红字 = test scale 包含在训练集中
| Test / Train | ×2 | ×3 | ×4 | ×2,3 | ×2,4 | ×3,4 | ×2,3,4 | Bicubic |
|---|---|---|---|---|---|---|---|---|
| ×2 | 37.10 | 30.05 | 28.13 | 37.09 | 37.03 | 32.43 | 37.06 | 33.66 |
| ×3 | 30.42 | 32.89 | 30.50 | 33.22 | 31.20 | 33.24 | 33.27 | 30.39 |
| ×4 | 28.43 | 28.73 | 30.84 | 28.70 | 30.86 | 30.94 | 30.95 | 28.42 |
红字 = test scale 已包含在训练集中(对角及多尺度联合训练) · Bicubic 列为基线
Fig. 5 · 视觉对比 — 顶: VDSR 多尺度单模型 · 底: SRCNN(×3 模型) 用于所有尺度
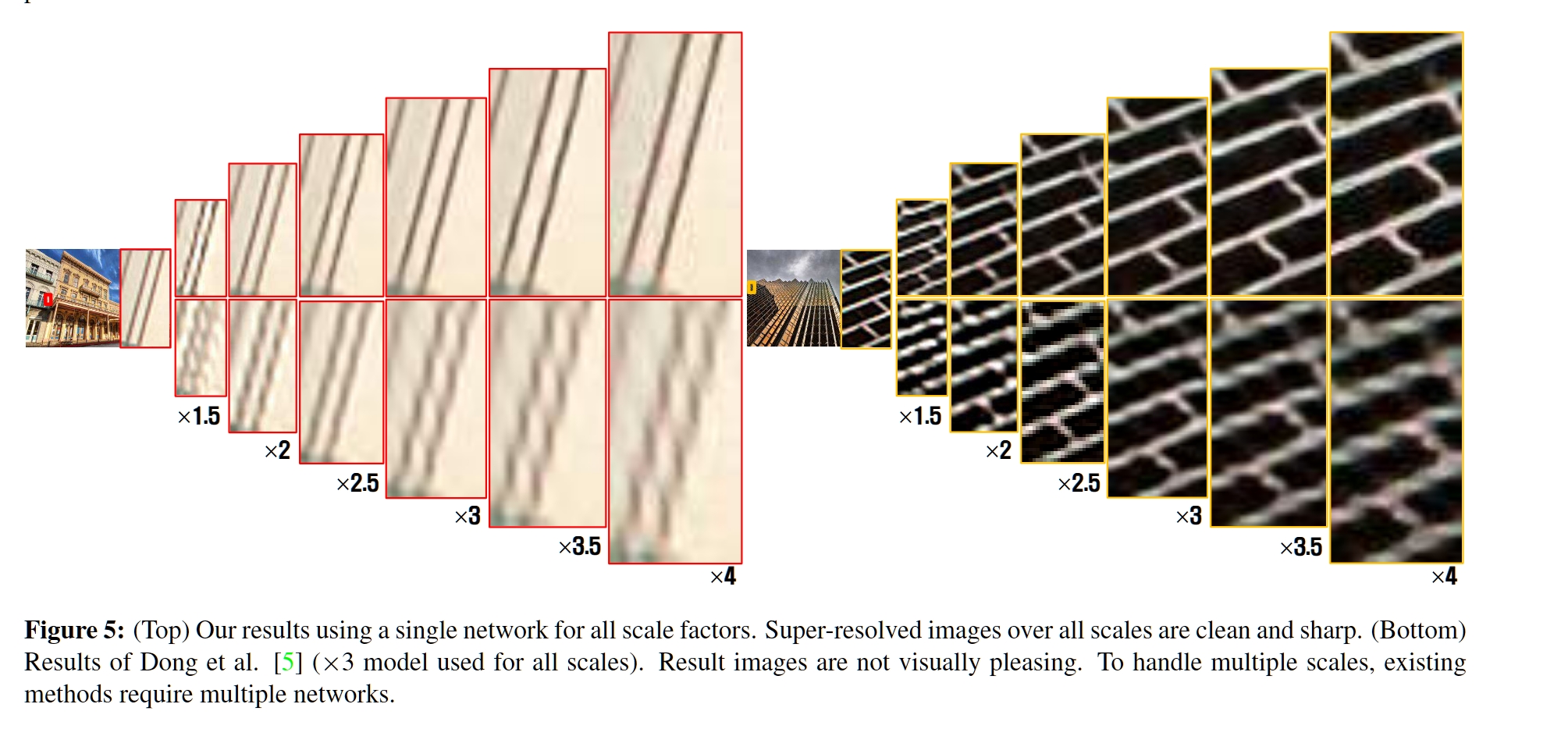
关键观察 · 对角 vs 非对角
非对角(红色):train×2 测 ×3 = 30.05 dB,远低于 bicubic (30.39) — 单尺度模型完全不能跨用。
对角: train×2 测 ×2 = 37.10 dB(最优)。
对角: train×2 测 ×2 = 37.10 dB(最优)。
★ 反直觉结论
train ={2,3,4} 测 ×2 = 37.06 dB ≈ 单尺度模型 37.10;测 ×3 = 33.27 > 33.22;测 ×4 = 30.95 > 30.86.
多尺度训练对大 scale 反而更好 — scale 数据互为正则化。
多尺度训练对大 scale 反而更好 — scale 数据互为正则化。
Fig 5 视觉:VDSR 在所有 ×1.5–×4 上线条干净锐利;SRCNN 用同一 ×3 模型推所有 scale ⇒ 明显模糊或畸变。
论文 5.4 给出 定量(Table 3)和 定性(Fig 6/7,下一页)两种对比。本页系统拆解 Table 3 — 包括对比方法、读表方法、关键发现,并讨论速度公平性的 caveat。
Table 3 · 四数据集 × 三 scale · PSNR / SSIM / 单图秒数 · 红=最优 · 蓝=次优
| Dataset | Scale | Bicubic | A+ [22] | RFL [18] | SelfEx [11] | SRCNN [5] | VDSR (Ours) |
|---|---|---|---|---|---|---|---|
| PSNR/SSIM/time | PSNR/SSIM/time | PSNR/SSIM/time | PSNR/SSIM/time | PSNR/SSIM/time | PSNR/SSIM/time | ||
| Set5 | ×2 | 33.66/0.9299/0.00 | 36.54/0.9544/0.58 | 36.54/0.9537/0.63 | 36.49/0.9537/45.78 | 36.66/0.9542/2.19 | 37.53/0.9587/0.13 |
| ×3 | 30.39/0.8682/0.00 | 32.58/0.9088/0.32 | 32.43/0.9057/0.49 | 32.58/0.9093/33.44 | 32.75/0.9090/2.23 | 33.66/0.9213/0.13 | |
| ×4 | 28.42/0.8104/0.00 | 30.28/0.8603/0.24 | 30.14/0.8548/0.38 | 30.31/0.8619/29.18 | 30.48/0.8628/2.19 | 31.35/0.8838/0.12 | |
| Set14 | ×2 | 30.24/0.8688/0.00 | 32.28/0.9056/0.86 | 32.26/0.9040/1.13 | 32.22/0.9034/105.00 | 32.42/0.9063/4.32 | 33.03/0.9124/0.25 |
| ×3 | 27.55/0.7742/0.00 | 29.13/0.8188/0.56 | 29.05/0.8164/0.85 | 29.16/0.8196/74.69 | 29.28/0.8209/4.40 | 29.77/0.8314/0.26 | |
| ×4 | 26.00/0.7027/0.00 | 27.32/0.7491/0.38 | 27.24/0.7451/0.65 | 27.40/0.7518/65.08 | 27.49/0.7503/4.39 | 28.01/0.7674/0.25 | |
| B100 | ×2 | 29.56/0.8431/0.00 | 31.21/0.8863/0.59 | 31.16/0.8840/0.80 | 31.18/0.8855/60.09 | 31.36/0.8879/2.51 | 31.90/0.8960/0.16 |
| ×3 | 27.21/0.7385/0.00 | 28.29/0.7835/0.33 | 28.22/0.7806/0.62 | 28.29/0.7840/40.01 | 28.41/0.7863/2.58 | 28.82/0.7976/0.21 | |
| ×4 | 25.96/0.6675/0.00 | 26.82/0.7087/0.26 | 26.75/0.7054/0.48 | 26.84/0.7106/35.87 | 26.90/0.7101/2.51 | 27.29/0.7251/0.21 | |
| Urban100 | ×2 | 26.88/0.8403/0.00 | 29.20/0.8938/2.96 | 29.11/0.8904/3.62 | 29.54/0.8967/663.98 | 29.50/0.8946/22.12 | 30.76/0.9140/0.98 |
| ×3 | 24.46/0.7349/0.00 | 26.03/0.7973/1.67 | 25.86/0.7900/2.48 | 26.44/0.8088/473.60 | 26.24/0.7989/19.35 | 27.14/0.8279/1.08 | |
| ×4 | 23.14/0.6577/0.00 | 24.32/0.7183/1.21 | 24.19/0.7096/1.88 | 24.79/0.7374/394.40 | 24.52/0.7221/18.46 | 25.18/0.7524/1.06 |
Table 3. Average PSNR/SSIM for scale factor ×2, ×3 and ×4 on datasets Set5, Set14, B100 and Urban100. Red color indicates the best performance and blue color indicates the second best performance.
对比方法 · 五个对手
Bicubic(基线 / 框架内置) · A+ [22, Timofte ACCV 2014] 字典锚点回归 · RFL [18, Schulter CVPR 2015] 随机森林 · SelfEx [11, Huang CVPR 2015] 自相似 patch · SRCNN [5, Dong ECCV 2014] 端到端 CNN
主要发现 · 全胜
12 / 12 PSNR 第一
4 数据集 × 3 scale = 12 项 · 大多领先 +0.3 ~ +1.3 dB。
三个亮眼数据
Set5 ×2: 37.53 vs SRCNN 36.66 · +0.87
Urban100 ×2: 30.76 vs 29.50 · +1.26 dB · 最大领先
B100 ×3: 28.82 vs 28.41 · +0.41 dB
Urban100 ×2: 30.76 vs 29.50 · +1.26 dB · 最大领先
B100 ×3: 28.82 vs 28.41 · +0.41 dB
速度对比的 caveat
VDSR 单图 0.13 s(Set5 ×3)— 比 SRCNN 公开版 2.19 s 快约 17×。
但论文明确写: SRCNN 公开版是 CPU 实现,比 Dong et al. 自家论文用的 GPU 实现慢。所以这个 17× 不能直接说成"VDSR 比 SRCNN 快 17×"。
VDSR 的核心贡献是精度(PSNR),不是速度。同年的 FSRCNN 才在速度上做文章。
但论文明确写: SRCNN 公开版是 CPU 实现,比 Dong et al. 自家论文用的 GPU 实现慢。所以这个 17× 不能直接说成"VDSR 比 SRCNN 快 17×"。
VDSR 的核心贡献是精度(PSNR),不是速度。同年的 FSRCNN 才在速度上做文章。
读 Table 3 的方法: 每个格子三行 = PSNR / SSIM / 单图秒数。红字 = 该 (dataset, scale) 上的最优,蓝字 = 次优。沿 VDSR 列(最右)从上到下看,几乎全是红色;沿任意 SoTA 列看,红字寥寥无几。
Fig. 6 · "148026" · B100 · ×3 — 屋顶斜线 · VDSR 恢复出连续线条

Fig. 7 · "38092" · B100 · ×3 — 野牛犄角 · VDSR 边缘最锐利

怎么读视觉对比
- 红框标出"难"区域(细线 / 锐边 / 高频纹理)
- 对比 GT 与各方法的放大裁切 — 越接近越好
- 注意 ringing / blur / 锯齿 / 重影
Fig 6 · 屋顶线条
A+ / RFL / SelfEx / SRCNN 都把斜线"模糊掉"或"错位";只有 VDSR 的红框中线条清晰可见、与 GT 几乎一致。
PSNR 23.50, SSIM 0.7777(最高)。
PSNR 23.50, SSIM 0.7777(最高)。
Fig 7 · 野牛犄角
其他方法犄角边缘明显模糊;VDSR 的轮廓锐利、对比度高,与 GT 最接近。
SSIM 0.7606(最高)。
SSIM 0.7606(最高)。
为什么 VDSR 视觉更好?大感受野 (41×41) 让网络"看到"整条线 / 整片纹理,能恢复出全局一致的结构;而 SRCNN 只能在 13×13 内拼接局部细节。
TAKEAWAY 01
深度就是性能
把 VGG 的"深度+小核"哲学搬到 SR:20 层全 3×3 · 感受野 41×41 · SoTA 12/12 第一。
TAKEAWAY 02
残差是关键钥匙
只学高频 \(r = y - x\),让深网可训练 · 大 lr · 快收敛 · 终点更高 — 后续 ResNet 等架构验证。
TAKEAWAY 03
单网络多尺度
参数共享 · scale 互为正则 · 部署友好 — 后续 EDSR / RCAN 继承这一思路。
SR 网络演进时间线
2014
SRCNN
3 层 · 端到端 CNN
HR 空间卷积
HR 空间卷积
→
2016 CVPR
VDSR ★
20 层 · 残差
多尺度共享
多尺度共享
→
2016 ECCV
FSRCNN
LR 空间卷积
实时 + 沙漏
实时 + 沙漏
→
2017+
EDSR / RCAN
残差 + 极深
注意力机制
注意力机制
+0.87
dB · Set5 ×2
dB · Set5 ×2
VDSR 用VGG 启发的极深架构 + 残差学习 + 高学习率 + 梯度裁剪,第一次把深度学习的全部红利带给超分。
"深度 + 残差"从此成为低层视觉任务的标准范式 — 直到今天的 SwinIR / HAT 仍在沿用。
"深度 + 残差"从此成为低层视觉任务的标准范式 — 直到今天的 SwinIR / HAT 仍在沿用。
局限:① 仍依赖 bicubic 预放大 ⇒ 计算量随 scale² 增长(FSRCNN 解决) · ② 网络平铺无分支,长程依赖弱(后续 SwinIR 等解决)